
Written by: Dr. Gagan Narula
At Earkick, we’re developing best free AI chat to empower our app users to better understand their mental health and proactively embrace self-care. Key steps in addressing mental health challenges include assessing an individual’s current state, providing a preliminary diagnosis and guiding them towards the right care pathway whether this is a psychologist, psychiatrist, or in-patient/out-patient clinic.
We believe AI has immense potential to revolutionize mental health care, serving as a valuable support tool for clinicians and mental health professionals. But are today’s AI models advanced enough to address the complex challenges faced by trained professionals?
In this blog post, we explore the results of experiments conducted on both large, closed-source models (LLMs) and smaller, open-source models (SLM’s) in the field of psychotherapy, psychology and mental health counseling.

OBJECTIVES
The primary objective of our experiments was to evaluate the knowledge that large and small language models have in the areas of clinical mental health assessment, diagnosis, and counseling. To evaluate this, we selected two prominent licensing exams, one approved by the National Board of Certified Counselors in the United States: the National Clinical Mental Health Counselor Exam (NCMHCE), and the other by Association of Social Work Boards, the ASWB exam.
Since access to the actual exams was not possible, we used practice exams from officially recognized providers as a substitute for the real tests. We purchased a license to these practice exams as they are not available for free.
We believe the level of domain knowledge and reasoning required to answer the practice questions is quite substantial, especially for the NCMHCE. Sample questions from the NCMHCE test are provided here. Each question presents a case study of an individual dealing with a mental health disorder, an addiction, or a family /relationship issue.
Each of these case studies is followed by a multiple choice question. Six distinct counseling domains are covered, including: Intake, Assessment, and Diagnosis (20–30%), Treatment Planning (10–20%), Counseling Skills and Interventions (25–35%), Professional Practice and Ethics (10–20%), Core Counseling Attributes (10–20%), and Areas of Clinical Focus, which represent the specific details provided in each case study.
The ASWB, on the other hand, assesses the knowledge of a social worker across multiple domains such as psychology, addiction and substance abuse, clinical assessment, statistics, management, and other related fields.
For the smaller language models, ranging from 2 billion (B) to 14B parameters, our goal was to test both the pretrained base models and to further fine-tune them using parameter-efficient training techniques on a curated dataset focused on psychology, psychiatry, and counseling, created by our Earkick AI team. We then compare the performance post-training to their pretraining scores and to other models.
With the current set of smaller models — such as Microsoft’s Phi-3 and 3.5 series, Meta AI’s Llama3.1 series, Google’s Gemma series and Qwen2.5 from Alibaba Cloud- the capabilities of small models on tasks like question answering, conversational dialogue, reasoning and multimodal QA have advanced significantly.
Therefore, we believe that thoroughly investigating the mental health counseling capabilities of these language models is essential, especially if they are to be used in medical applications such as screening, diagnosis, intervention and referral.
Low Rank Adapters (LoRA) Fine-Tuning Methodology
Before we dive into the results, let’s quickly review the training methodology used. Fine-tuning large language models on specific tasks often demands substantial computational resources. To mitigate this, we employed the Low Rank Adapters (LoRA) fine-tuning method.
LoRA reduces the number of trainable parameters by representing weight updates as low-rank matrices. This approach not only speeds up the fine-tuning process but also minimizes memory usage, making it ideal for adapting large models.
Formally, if a linear layer in a deep network performs the following operation:
Y = W⋅X
Where X is an h x d dimensional input, W is an o x h matrix of learnable parameters and Y is an o x d dimensional output. (o = output dimensionality, d = input dimensionality, h = hidden layer dimensionality) LoRA introduces a pair of fine-tuneable rank ‘r’ matrices A (o x r) , B (r x h) such that:
Y = (W + A⋅B)⋅X
The reduction in the number of new parameters comes from the rank r being much smaller than d (r << d). Although the default value of r is typically 8, in our experiments, we treated r as a hyper-parameter and adjusted it to find the optimal value.
Experiment details
Model choices for evaluation only, without fine-tuning:
- mistralai/Mistral-Nemo-Instruct-2407
- microsoft/Phi-3.5-MoE-instruct
- google/gemma-2–9b-it
- OpenAI gpt-4o
- OpenAI gpt-4o-mini
- Google gemini-1.5-pro
- Anthropic Claude Sonnet 3
- Meta Llama3.1 405B
Model choices for evaluation and fine-tuning. We fine-tuned the following open-source models available on the HuggingFace hub:
- meta-llama/Llama-3.1–8B-Instruct (128k context window, 8B parameters)
- microsoft/Phi-3.5-mini-instruct (128k context window, 4B parameters)
- microsoft/Phi-3-medium-128k-instruct (128k context window, 14B parameters)
- Qwen/Qwen2.5–7B-Instruct (128k context window, 7B parameters)
Training Dataset
The training dataset created by Earkick is a high quality, curated, deduplicated collection totalling 5.2 million tokens (as tokenized by the Llama3.1 tokenizer), composed of the following components:
- Psychlit: Literature on psychology, psychiatry, neurobiology, psychopathology, and therapy techniques sourced from trusted, openly available resources such as the National Institutes of Mental health (NIMH), peer reviewed open-access publications like the Annual Reviews of Psychiatry, the DSM-V manual, and other psychology and psychotherapy journals and books. We annotated passages extracted from these sources with topic tags and titles using OpenAI’s gpt-4o. After curation, we filtered the dataset to remove poorly formatted passages, short sentences (< 600 tokens), and bibliography, figures, figure captions and table of contents.
- NCE: A National Counselor Examination practice exam. While its focus differs from the NCMHCE and ASWB, it still falls within the domain of counselor licensure.
- Syn: Synthetic data generated from closed-source models such as OpenAI gpt-4o, Google Gemini 1.5 pro, and Claude 3 Sonnet. We prompted these models to generate multiple choice questions from the subject domains tested by the Examination for Professional Practice in Psychology (EPPP).
- NCMHCE: A small number of NCMHCE practice questions.
- ASWB: ASWB practice questions (non-overlapping with the evaluation set below). These questions were followed by the right answer choices along with an explanation or reasoning by the exam authors. Therefore, the models were fine-tuned not only on the questions and answers, but also on the rationale behind the correct answers.
Evaluation Dataset
The evaluation dataset for all models consisted of a combination of 202 NCMHCE practice exam questions and 81 ASWB practice exam questions.
Training script
We adapted this script from the HuggingFace Transformers trl library for supervised fine-tuning. Models were evaluated on the evaluation datasets during training, implementing early stopping and assessing the best model checkpoint after training.
Training hyper-parameters
Fixed hyper-parameters:
- Effective batch size with gradient accumulation = 128
- LoRA target modules = “all linear”
- AdamW optimizer, max learning rate = 2e-4, cosine learning rate scheduler with no warm-up.
- All model parameters were quantized to 4-bit precision, and the training precision was “bfloat16”.
- Seed was fixed to 100 for all experiments.
- Evaluation temperature was always 0.1, with sampling allowed. Max new tokens was 256 for models running on GPU and 1024 for api based, larger models.
Modulated hyper-parameters:
LoRA ‘r’ (rank) values tested: [8, 16, 32, 64, 128]. We performed initial experiments on a validation set drawn from the training set NCMHCE and ASWB questions. LoRA alpha (scaling coefficient) was fixed to twice the LoRA r.
Hardware
All experiments were conducted on a single NVIDIA A6000 GPU.
Note on the evaluation
System or instruction prompts: All training and testing samples included an instruction or “system” prompt. For models like Gemini, which do not support a separate system message, we concatenated the instruction with the user message. For local models using the HuggingFace api, we employed the tokenizer.apply_chat_template() function.
We implemented Chain-of-thought prompting, asking models to generate both the answer to the question (a single uppercase letter like “A” or “B”) and a rationale for their choice.
To facilitate valid JSON output, we used libraries like jsonformer, outlines, and instructor to guide the models. In cases where a model’s output did not produce valid JSON (resulting in a parsing error), we corrected the output to {“answer”: “A”, “reason”: “”}.
We refrained from providing a random answer in these instances, as this would complicate comparison between models. Note that, we did not observe any JSON decoding errors from any model after applying the aforementioned libraries.
Experiment Results and Analysis
As previously mentioned, our focus was on evaluating performance of both pretrained large and small language models (LMs) and the post-training performance of the small LMs. The accuracy for each test dataset, along with the average accuracy, is presented in the table below. For models that underwent fine-tuning, we also indicate the gain (or loss) in accuracy in percentage points compared to the base, pre-trained model before fine-tuning.
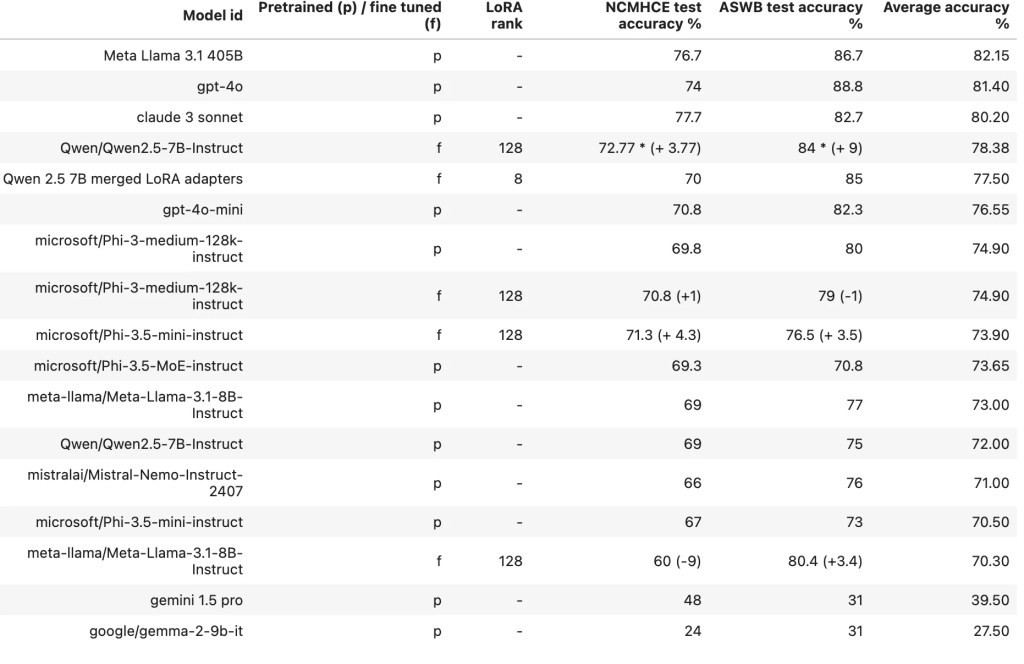
Fine-tuned SLMs Narrow the Gap to LLMs
Table 1 demonstrates that, as expected, the large language models achieve the best performance on the NCMHCE and ASWB tests, with the open source Llama 3.1 405B model standing out as the top performer overall. However, a fine-tuned Qwen 2.5 7B model surpassed the performance of gpt-4o-mini after fine-tuning, coming very close to matching the accuracy of Claude 3 Sonnet. This indicates that fine-tuning on our dataset generally increases the accuracy of the small LMs, as shown by the increase in accuracy percentage points in Table 1.
Curated psychology literature data in a non-QA format still provides benefits
We conducted additional experiments with the Qwen 2.5 7B model to investigate whether the inclusion of psychology literature (“psychlit”), the largest component of our dataset, improved the evaluation accuracy, even though this subset was not formatted as question-and-answer (QA) data. To test this, we created a version of our dataset excluding this subset, which reduced the sample count from 8,071 to 1,899 and the number of tokens from 5.2 million to 0.845 million.
Our findings reveal a significant reduction in the accuracy of the Qwen 2.5 model (maintaining the same architecture including LoRA adapters) trained on this version of the dataset, with achieving 67% on NCMHCE and 76.5% on the ASWB, resulting in an average accuracy of 71.75% compared to 78.38% for the model trained on the full dataset. Therefore, our curated selection of psychology, psychiatry, and mental health-related literature and peer reviewed publications indeed enhances model generalization.
Merging LoRA adapters still yields performance gains
We also explored whether training separate LoRA adapters for the Qwen 2.5 model on each subset of the dataset and then merging them could achieve comparable evaluation accuracy. We trained models on each of the five data subsets individually, and then combined them using the “dare ties” adapter merging technique.
By assigning adapter weights of [3, 1.5, 1., 1.5, 1.] to the datasets [NCMHCE, ASWB, Syn, NCE, Psychlit] respectively, and applying a weight density of 0.2 after pruning, the resulting model achieved 70% accuracy on the NCMHCE test set and 85% on the ASWB test set, averaging 77.5, just 0.879 percentage points lower than the model trained on the full dataset! Remarkably, the LoRA rank for each individual adapter was kept low (r = 8) versus (r = 128) for the larger model, highlighting that merging adapters has significant efficiency advantages.
Conclusion
Our experiments have highlighted several key insights:
- Gap in knowledge and reasoning capabilities: Both, large and small language models still have limitations in knowledge and reasoning when applied to psychology, therapy or counseling tasks. Overcoming these limitations requires higher-quality, domain-specific datasets and architectural improvements, such as test-time compute and learning-to-reason techniques, as shown recently by the release of OpenAI’s GPT-o1. Despite this, with a majority of models already achieving average accuracies between 75% and 83%, they may achieve the minimum passing score set by the NBCC. It’s not entirely clear if they would pass because the NBCC chooses 100 questions for scoring and decides passing cut-offs independently by a post-hoc examination of test questions by subject matter experts. A quick look at anecdotal reports online suggests a cutoff between 61 and 70%.
- Small language models are indeed highly capable, already at the 7 billion parameter range and can close the gap to large models when fine-tuned using parameter efficient techniques on highly quality datasets.
- LoRA model merging is an excellent way to build a single model in a multi-task environment.
Caveats
Firstly, a flaw of our experiments is that we did not fine-tune the large, closed source models, or test them in a retrieval augmented generation (RAG) setting using our training dataset as a vector database, making performance comparisons not entirely fair. However, since LLM providers do not provide information on the full extent of their training data, one could equally assume that the benchmarks we use (along with our other training data subsets) could be found within their training data.
Secondly, due to compute and time constraints, we were not able to test all models in few shot settings, with all our experiments being conducted in a zero-shot setting. It has been shown that In-context Learning dramatically improves model performance, which we aim to explore in future experiments.
Outlook
In subsequent work, we’ll be looking at the following questions:
- What can the reasoning traces generated by the LMs tell us about how the models arrived at their decisions ?
- What kinds of errors do the models make ? Are the model choices close to the correct answer, given that the “correct” answer in many case studies and psychology scenarios is not always considered the best answer by every counselor ?
- Are there any consistent biases in the model outputs ? For example, race and gender are included in the Intake portion of the NCMHCE case study questions. Do the models show biases related to these pieces of information ?
We’ll provide answers to these questions in a subsequent blog post! Stay tuned.
Acknowledgements
This work would not have been possible without the excellent trl, peft, bitsandbytes and transformers libraries, so we’d like to thank the HuggingFace team for supporting and propelling open source models and AI/ML research forward!